- позволяют увеличить размер и сложность программ, выполняемых на рабочей станции;
- обеспечивает перенесение наиболее трудоемких опе-раций на сервер, являющийся машиной большей вычислительной мощности;
- уменьшает до минимума возможность потери содержащейся в БД информации за счет применения имеющихся на сервере внутренних механизмов защиты данных , таких , как , например системы трассировки транзакций, откат после сбоя, средства обеспечения целостности данных;
- в несколько раз уменьшает объем информации, передаваемый по сети.
- высокая производительность
- масштабируемость
- смешанная загрузка сервера разными типами задач
- непрерывная доступность данных
- снижение нагрузки на операционную систему (число серверных процессов невелико);
- сокращение совокупной потребности клиентов в оперативной памяти;
- снижение конкуренции при одновременном использовании системных ресурсов;
- более рациональное по сравнению с ОС назначение приоритетов и планирование;
- равномерная загрузка наличных процессоров;
- ускорение обработки сложных запросов за счет параллельного выполнения на нескольких процессорах.
-
>
- ввод-вывод логической журнализации - наивысший приоритет;
- ввод-вывод физической журнализации - второй по значимости приоритет;
- прочие операции ввода-вывода- низший приоритет.
- когда он временно не может выполняться, например, если необходимо дождаться завершения обмена с диском, ввода данных от клиента, снятия блокировки.
- когда в коде потока встречаются обращения к функции yield. Обращения к ней вставляются при компиляции запросов, требующих длительной обработки, чтобы их выполнение не тормозило прохождение других потоков. Для этого выбираются точки, наиболее безболезненные для выполнения потока.
- Очередь готовых к выполнению потоков.
- Очередь спящих потоков. В нее помещается, например, CPU-поток, которому требуется доступ к диску. Предварительно CPU-поток порождает запрос на обмен с диском, для обслуживания которого формируется AIO-поток. Завершив обмен с диском, AIO-поток оповещает об этом виртуальный процессор CPU, который "будит" спящий CPU-поток и перемещает его в очередь готовых потоков.
- Очередь ждущих потоков. Эта очередь служит для координации доступа потоков к разделяемым ресурсам. В нее помещаются потоки, ожидающие какого-либо события, например, освобождения заблокированного ресурса. Когда поток, заблокировавший этот ресурс, готов освободить его, просматривается очередь ждущих потоков. Если в ней есть поток, ожидающий именно этот ресурс, то он перемещается в очередь готовых.
- Снизить общее потребление памяти, поскольку участвующим в разделении процессам, т. е. виртуальным процессорам, нет нужды поддерживать свои копии информации, находящейся в разделяемой памяти.
- Сократить число обменов с дисками, потому что буферы ввода-вывода сбрасываются на диск не для каждого процесса в отдельности, а образуют один общий для всего сервера баз данных пул. Виртуальный процессор зачастую избегает выполнения или обращения за результатами операций ввода с диска, поскольку нужная таблица уже прочитана другим процессором.
- Организовать быстрое взаимодействие между процессами. Через разделяемую память, в частности, обмениваются данными потоки, участвующие в параллельной обработке сложного запроса. Разделяемая память используется также для организации взаимодействия между локальным клиентом и сервером.
- собственное управление дисковой памятью;
- асинхронный ввод-вывод;
- опережающее чтение.
- Снятие ограничений операционной системы на число одновременно читаемых таблиц.
- Оптимизация размещения таблиц - для таблиц выделяются большие области последовательных физических блоков, в результате ускоряется доступ к ним.
- Снижение накладных расходов при чтении - данные с дисков считываются непосредственно в разделяемую память, минуя буферы ОС.
- Повышение надежности. При использовании файловой системы INFORMIX-OnLine DS не может гарантировать, что в случае сбоя данные журнала транзакций не пропадут из-за того, что они остались в буферах ОС и не успели записаться на диск. Поэтому процедура быстрого восстановления, вызываемая при перезапуске системы, не обеспечит в этом случае целостности данных.
- Сокращается время обработки одного запроса. Встроенный в INFORMIX-OnLine DS механизм PDQ при обработке запросов использует информацию о фрагментации таблиц и создает для сканирования таблицы несколько параллельных потоков. Если стратегия фрагментации выбрана удачно, то ускорение при выборке из таблицы практически линейно зависит от числа фрагментов (рис. 3).
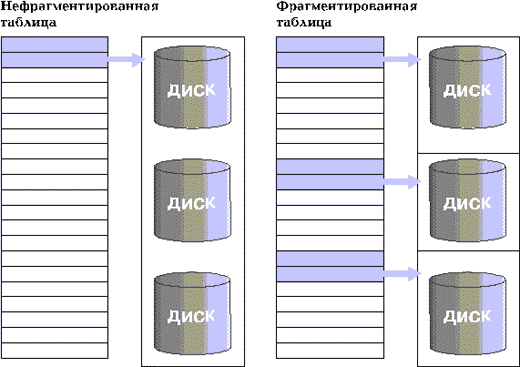
- Снижается уровень конкуренции при одновременном обращении нескольких запросов к одной таблице. INFORMIX-OnLine DS анализирует правило фрагментации таблицы и во многих случаях способен определить, что данный запрос относится только к одному ее фрагменту. Если фрагменты хранятся на разных дисковых устройствах, то разным запросам будут соответствовать обращения к разным дискам.
- Повышается готовность (доступность) приложений. Даже если некоторые фрагменты таблицы недоступны из-за того, что соответствующие диски вышли из строя, запросы к ней, тем не менее, во многих случаях могут выполняться.
- Улучшаются характеристики административных операций, таких как архивирование-восстановление, загрузка-выгрузка данных, поскольку они применимы к отдельным фрагментам таблиц. Если таблица разбита на малые фрагменты, то ее восстановление при выходе из строя одного фрагмента выполняется значительно оперативнее, чем полное восстановление нефрагментированной таблицы. Полные операции архивирования, восстановления, загрузки, выгрузки данных также ускоряются, поскольку операции ввода-вывода для фрагментов таблицы выполняются параллельно.
- Равномерное распределение (round robin) - это встроенный в INFORMIX-OnLine DS механизм фрагментации, который обеспечивает примерно равное число записей в каждом фрагменте.
- Распределение по выражению (by expression) - для каждого фрагмента задается некоторое выражение, зависящее от значений полей записи; истинность выражения определяет, попадет ли запись в данный фрагмент.
- Распределение данных по фрагментам;
- Баланс запросов на ввод-вывод по фрагментам;
- Статус дисковых областей, содержащих фрагменты.
- обработка сложных запросов, включающих сканирование больших таблиц, сортировку, соединения, группирование, массовые вставки;
- построение индексов;
- сохранение и восстановление данных;
- загрузка, выгрузка данных, реорганизация баз данных;
- массовые операции вставки, удаления, модификации данных.
- Параллельный ввод и вывод (на основе горизонтальной фрагментации таблиц).
- Распараллеливание отдельных итераторов (на основе методов разбиения данных).
- Распараллеливание плана выполнения запроса (путем разбиения дерева реализации запроса на независимые поддеревья; за счет применения техники потоков данных).
- Снижение вычислительной сложности алгоритмов (применение основанных на хешировании алгоритмов сортировки, соединения, вычисления агрегатных функций (sum, min, max, avg, ...)).
- Управление ресурсами, регулирование степени распараллеливания (под PDQ выделяется определенная доля системных ресурсов).
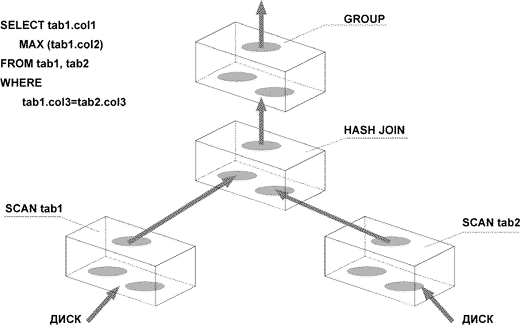
- устанавливает приоритет каждого запроса;
- следит за тем, чтобы одновременно выполнялось не более заданного числа PDQ-запросов;
- следит за тем, чтобы объем разделяемой памяти, занятой под обработку сложных запросов, не превышал заданного уровня;
- совместно с оптимизатором запросов обеспечивает максимальную при заданных параметрах степень параллелизма на всех уровнях.
- Зеркалирование дисковых областей
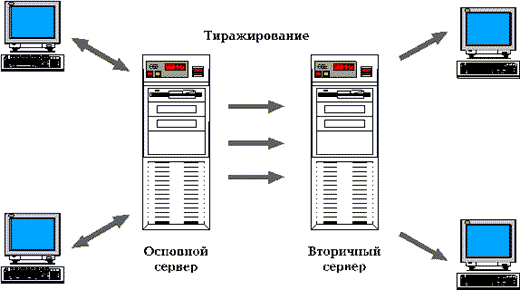
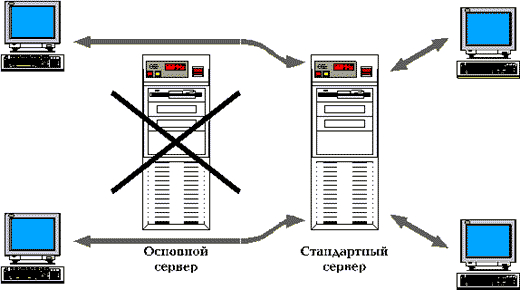
- Полное тиражирование данных сервера
- Быстрое восстановление при включении системы
- Средства архивирования данных